

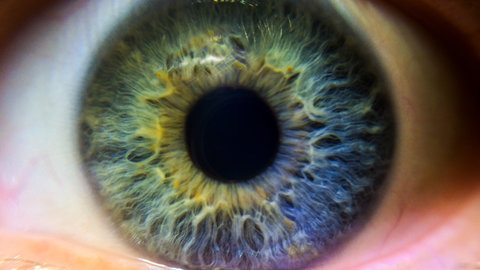
Neuroscientist Kalanit Grill-Spector studies the physiology of human vision and says that the ways computers and people see are in some ways similar, but in other ways quite different.
In fact, she says, rapid advances in computational modeling, such as deep neural networks, applied to brain data and new imaging technologies, like quantitative MRI and diffusion MRI, are revolutionizing our understanding of how the human brain sees. We’re unraveling how the brain “computes” visual information, as Grill-Spector tells host Russ Altman on this episode of Stanford Engineering’s The Future of Everything podcast.
[00:00:00] Kalanit Grill-Spector: At the end of the temporal lobe, there’s a system that’s involved in visual recognition. Within that system, there are multiple regions and one of them, or several of them, are actually, um, specialized for processing, uh, faces. Other regions are specialized for processing objects or words or places, and even body parts.
[00:00:26] Russ Altman: This is Stanford Engineering’s The Future of Everything and I’m your host Russ Altman. If you [00:00:30] enjoy The Future of Everything podcast, please follow or subscribe wherever you listen to your podcasts. This will guarantee that you never miss an episode and are never surprised by the future of anything.
Today Kalanit Grill-Spector will tell us how imaging technologies and computing are revolutionizing our understanding of how the human visual system works.
How do we recognize faces, objects, and places? How do we map out the functions of the brain? It’s the future of human vision.
Before we jump into [00:01:00] this episode, just a reminder to please rate, review and follow the podcast. It will help others discover us and it’ll also help us grow.
We hear a lot about the amazing capabilities of computers and phones at recognizing faces. In fact, I can’t even get onto my phone until it recognizes my face. But the OG facial recognition, the original is the human brain. Has the human brain evolved to recognize [00:01:30] faces, or have we just seen so many faces that we get really good at it?
Also, how does the brain look at a face and immediately bring back memories of loved ones, specific places, specific situations, fear and anxiety? It’s in all-encompassing, complicated system.
Kalanit Grill-Spector is a professor of psychology at Stanford University and her group uses imaging and computing to study the visual system of the brain. She [00:02:00] focuses on facial recognition, but also looks at reading and word recognition, and even Pokemon.
Kalanit, you focus on the visual system In your work and in particular, you’ve spent a lot of time looking at how we recognize faces. This has kind of been in the news recently because there are all these AI systems that are recognizing faces, but let’s go back to the brain. Is the way the brain recognize faces anything like the way computers do it, or is it an entirely different approach?
[00:02:29] Kalanit Grill-Spector: I’d say a little [00:02:30] bit of both. Um, a lot of the modern and eye systems are really inspired by the brain and these deep neural networks these convolutional neural networks are inspired by the architecture of the brain. However, the details, uh, of the systems, the architecture are very different between the computer system and the brain. And this is both interesting and, for the CS part and for the neuro science part at the same time.
[00:02:58] Russ Altman: Great. So let, let’s focus on the [00:03:00] brain because we can have other conversations about AI uh, later.
Um, what do we know, uh, where are we in our understanding of how the visual system processes things like a new face or an old face? Uh, and what are the big challenges facing you on the research side?
[00:03:15] Kalanit Grill-Spector: So there’s been a lot of advances, uh, especially in the last 25 years, uh, with, um, invention of functional MRI, that lets us look into people’s brain, uh, live when they’re looking at images like faces or cars or planes [00:03:30] or places. And what we know is that when the input hits your eyes, it gets transferred to the brain. And then there’s a series of processing stages across what we call a visual hierarchy. Meaning information gets transformed from one visual area.
The first visual area is V1 to the next visual area, V2, and so on. And it goes through from the occipital lobe, which is in the back of your brain to the bottom of your temporal lobe. Um, and then at the end of the temporal lobe, there’s a system that’s involved in visual recognition. Within that [00:04:00] system are multiple regions, and one of them, or several of them, are actually, um, specialized for processing, uh, faces other regions are specialized for processing objects or words or places and even body parts.
[00:04:13] Russ Altman: So it’s interesting that we have a dedicated place in our brain for faces, and I guess that means evolutionarily it was super important to make sure we knew who we were dealing with.
[00:04:25] Kalanit Grill-Spector: So this is actually a question of intense debate whether a [00:04:30] specialization is, has developed over evolution or because we see early on a lot of faces since we were born,
[00:04:36] Russ Altman: Umm.
[00:04:36] Kalanit Grill-Spector: We developed this expertise because it’s kind of important, we call it the visual diet. Like what kind of, what is the frequency and importance of stimuli that you visually see during your lifetime? So part of the debate is that’s been ongoing is how much is it carved by evolution, the specialization versus how much it’s learned through your daily experiences.
[00:04:57] Russ Altman: Okay, but I interrupted. Please go on. So [00:05:00] now you’ve said it kind of travels through the brain and it winds up in this area that for some reason or another seems to be focused and specializing in faces. Um, what, what happens there?
[00:05:12] Kalanit Grill-Spector: So it turns out that it’s not, what’s there happens is that this whole process is, and this is where it’s analogous to the eye system, the information gets transformed, uh, from, in their presentations that’s not perceptually useful in your retina or in your early visual cortex, like, V1 one into a [00:05:30] representation that’s more useful for recognition and for classifying different categories of stimuli.
And basically in these high level of regions, information is more abstracted from the physical image. For example, if you take two images of the same person, they’re not gonna be identical and it’s gonna be very hard for a computer to save the same face, or not just on the pixels on the picture, but once it gets to these high level visual areas, the representation of these two pictures are of the same person are gonna be very similar. And that’s gonna help you [00:06:00] recognize.
[00:06:00] Russ Altman: Yes.
[00:06:00] Kalanit Grill-Spector: That’s the same person.
[00:06:02] Russ Altman: So I know that. Um, one of the things as a human, I noticed…
[00:06:07] Kalanit Grill-Spector: Yes.
[00:06:07] Russ Altman: …that there are certain faces that immediately evoke a huge, um, non-cognitive, I mean non-cognitive, like emotional responses. So I happen to have two grandchildren and looking at their faces, does many things to me physiologically.
Do we understand how that happens? Because there are other people, like when I’m walking down the street in New York City, literally hundreds of faces elicit. [00:06:30] No reaction. So there must be some connections between these facial recognition events and kind of emotional centers of the brain.
[00:06:38] Kalanit Grill-Spector: That is definitely true. So there are connections to the memory systems that are involving, like the perianal cortex, the hippocampus or memory systems that invoke the sense of familiarity. So sometimes you might have a sense of deja vu, where it’s somebody that you don’t really know who they’re
[00:06:52] Russ Altman: Right.
[00:06:53] Kalanit Grill-Spector: But they kind of in sense of familiarity. And there are also connections between these face areas and also visual [00:07:00] areas like primary visual cortex with amygdala and amygdala is very much tied to the emotion…
[00:07:05] Russ Altman: uh.
[00:07:06] Kalanit Grill-Spector: …that you’re feeling.
There are other face areas also in the superior temporal lobes that are involved not in recognizing other aspects of faces, like for example, your intention, your gaze,…
[00:07:17] Russ Altman: Oh.
[00:07:17] Kalanit Grill-Spector: …your expression. And it seems that, that is also separated in different, uh, face clusters in the brain.
[00:07:25] Russ Altman: Yes. Now, um, so, great. So that gave us a nice overview of that.
[00:07:30] This is really quite an amazing system. Um, you mentioned before, uh, that, uh, there’s faces, but there’s also objects and places. Um, Are the, are, is the brain processing these in similar ways or does it have very different ways of doing the face, uh, kind of inferencing versus places or objects?
[00:07:50] Kalanit Grill-Spector: So I think with faces and places, there are some things that are done in parallel. And this is kind of why I believe that these [00:08:00] systems are actually segregated on the cortex because you might be in your room in New York, or you might be walking in the streets, or you’d be the same person in different places. So I might wanna extract the place information separately from the face information.
Second of all, uh, when you’re looking at people, you tend to look at their face because you need to see the details. And it turns out that our vision is not uniform. Our, we see much better at the center of our gaze than at the periphery. So the places are always [00:08:30] all around you.
[00:08:30] Russ Altman: Right? Right.
[00:08:31] Kalanit Grill-Spector: They take entire vision.
[00:08:32] Russ Altman: Panorama. Panorama.
[00:08:33] Kalanit Grill-Spector: Yeah. So it turns out that the, there is some specialization early on in these regions that the regions that be turn to be face selective really process the center of gaze, the fovea, whereas regions that process the places are really processing the periphery and that is something that can be probably evolutionary, kind of determined by genetic gradient and stuff like that.
And your experience with the world might kind of form these [00:09:00] representations on these relevant. Uh, regions of cortex later on.
[00:09:05] Russ Altman: So I know that. Okay. So that was, that’s great. And that sets us up for my next question, which is, I know that one of the things you’re excited about are the new technologies that are emerging to allow you to do your work in ways that might not have been possible.
So can you take us through some of the biggest new technologies and how you’re using them to, uh, unravel these mysteries of visual perception and cognition?
[00:09:27] Kalanit Grill-Spector: Yes, I’m super excited about these new [00:09:30] technologies, uh, for several reasons. Um, when I started, I was really interested in how the brain function and what kind of representations might be in the brain that enable us, and this is kind of the conversation that we’re having.
But as I’ve become. More expert in my field. I realize that we need to look also at the structure of the brain, and we also need to better understand the computations. So I’m really interested in this interface between brain function, brain structure, and computation, and how that might lead to behavior.
[00:09:57] Russ Altman: Just to clarify, do you mean computation in a [00:10:00] computer or the way that the brain is doing the computations?
[00:10:03] Kalanit Grill-Spector: So I’m interested in, the brain is using computations, but we’re using computer models to predict the brain computations.
[00:10:09] Russ Altman: Okay, so kind of both.
Okay.
[00:10:10] Kalanit Grill-Spector: Yeah. And in terms, so when I’m talking to you about like computations, it can be very abstracted from the physical thing. And you know, the computers are really good. They might be even better than people, but they require a lot of power and a lot of compute power. And as human beings, we’re very metabolic efficient. Our brains fit into a [00:10:30] kilogram or something. Uh, our skull size is finite. We eat like maybe 3000 calories a day.
Uh, we’re very efficient organism, brain takes about maybe 10 to 20% of the metabolism. So, um, it’s expensive. So we have to be very efficient. So one of the things that, um, we’ve been looking at with these new technologies is to understand how structure and functions are related, and especially how that changes across development because it turns out that brain activity could affect brain [00:11:00] structure and getting some insights of how that might happen in the developing brain is a very, very exciting, in my point of view.
Um, how are we measuring that? Yeah, so some of these technologies, uh, so we use functional MRI to look at brain activity. There are also these new technology, is that look at brain structure more, uh, precisely. They’re called quantitative MRI, uh, and diffusion, MRI. So diffusion MRI, lets us looks at the connections between rain areas, these long-range [00:11:30] connections, uh, um, they tend to be insulated by myelin.
Um, that helps the transmission and then quantitative MRI gives us some, uh, access to the tissue properties. And we might get things like, How much myelin is there iron in different parts of the brain and how these structures might change over time and over the lifespan.
[00:11:50] Russ Altman: So you’ve mentioned functional MRI a couple of times.
What is where, what is the functional part of Functional MRI? So many of us are familiar with MRI. [00:12:00] It’s the scanner we go in, they take pictures of our brains. What makes it special and functional?
[00:12:05] Kalanit Grill-Spector: So in, uh, an anatomical MRI, you’re measuring the differences in different tissue contrast. So some tissues are more fatty, some tissues, uh, are more dense, and you can pick that up with an anatomical MRI that you’d go in the clinic.
Um, when your brain does, uh, mental activity, uh, it is again, metabolically expensive and you need, uh, oxygen. So the brain, um, has an overshoot of oxygen to enable [00:12:30] brain activity. And what we’re measuring with functional MRIs called bold blood, oxygen level defendant. So we’re measuring an indirect signal of brain activity.
We cannot measure as a neurons firing directly, but we can measure as their energy, uh, uptake. And that’s a signal that we’re measuring was functional MRI.
[00:12:47] Russ Altman: Okay. And, and I think. Some people may have seen these pictures where you have kind of an MRI in the background, black and white, but then there are these colorful regions.
And you say, when when I ask somebody to think about their mother’s [00:13:00] face, this is what, uh, lights up in the brain. Is that, is that the kind of thing we’re talking about?
[00:13:04] Kalanit Grill-Spector: So yes and no. Uh, so in the early days of FMRI, we were trying to understand which regions might be active in the brain in different tasks. So we would contrast activation to faces versus other stimuli like bodies or words or places. But we’ve really advanced, especially in the last 10 years in computational models, which means that we can take an image and write a deep neuro network that would predict the response to that image in each [00:13:30] voxel or volume pixel in the brain.
And these are called image computable models. So we have predictive power of predicting the response to a new stimulus, let’s say a new face, uh, or um, Something like that. So we’ve made a lot of headway and that’s kind of why I’m interested in the new computational uh, technologies as well.
[00:13:49] Russ Altman: So that sounds amazing.
I just wanna pause there to make sure I can understand this new idea, which is that every area of the brain might have some, a small amount of activity in response to a stimulus, and you’re [00:14:00] now able to not only map that. Uh, experimentally measuring it, but then go back and predict it for, uh, before you even make the measurements.
[00:14:08] Kalanit Grill-Spector: That is accurate. Yes.
You asked me how do computational models help me. I developed these models and I wanna see how good they are predicting activities and different kinds of experiments, new stimuli, and that’s really an exciting area of research.
[00:14:22] Russ Altman: Yes. And so can I ask for a summary of that? So what are we learning, uh, about our ability to make these predictions? [00:14:30] And, uh, I’m sure you find surprises every now and then where the prediction is kind of terrible. What are the kinds of situations that are very challenging for you?
[00:14:38] Kalanit Grill-Spector: I think we’re really good at predicting categories. So if we show, if you show a bunch of stimuli and you have to say, can, looking at somebody’s brain, let’s say, put you in the scanner. I look in your brain. Can I show you something? Can, I guess what you’re looking at? So I can guess pretty good if you’re looking at a face or a word or a car, the category.
It’s much harder to predict a specific facials. I suppose you’re looking [00:15:00] at maybe your grandchild’s, uh, face. Uh, I might be able to tell it’s a child face, but I might not. Be able to tell whose face it is. There’s been exciting papers that have come up and maybe in the last six months, three groups, uh, in bio archives that they’ve started to actually try to reconstruct from brain responses, specific images. And I think that’s really, uh, exciting as this has been, uh, possible.
Also, not just because of technology, but [00:15:30] because of big datasets. So a big dataset that has been collected by Kendrick Kay from the University, uh, of Minnesota together with Emily Allen. They’ve now scanned eight people while as they looked at 10,000 different images each. So that gives us enough power to, cuz these models have a lot of parameters.
[00:15:47] Russ Altman: Yes.
[00:15:47] Kalanit Grill-Spector: So that has also advanced field in a big way, uh, because they’re measuring really small voxels that are smallers and a millimeter and for many many images that give us power to build better models.
[00:15:59] Russ Altman: So that [00:16:00] raises the issue of, um, the generalizability of these models. So, um, do you have to study an individual, you know, however many thousands or hundreds of images in order to make predictions on that individual only, or does what you learn about that, that individual transfer to other individuals so that you could predict for them without having the same background data?
[00:16:22] Kalanit Grill-Spector: So this is a great question cuz what we’re doing when we’re developing the models, we’re setting benchmarks and our benchmark is how [00:16:30] much one brain is able to predict another brain.
[00:16:32] Russ Altman: Exactly.
[00:16:33] Kalanit Grill-Spector: Cause we can do better than that. So that’s a benchmark that we’ve been using. Um, and that’s been, uh, Like this is the best that we can get right now we’re not quite there yet, so I’d say we’re like 50% of the way. So we still have a way to,
[00:16:48] Russ Altman: but, but just to go a little bit deeper, but it is true that, um, observations on individual A will be helpful at reading the mind, I hate to use that term [00:17:00] of individual B uh, but it’s just not perfect.
[00:17:03] Kalanit Grill-Spector: Absolutely.
[00:17:04] Russ Altman: What about differences?
[00:17:05] Kalanit Grill-Spector: Cause .Just to give you a sense of why that…
[00:17:07] Russ Altman: Yes.
[00:17:08] Kalanit Grill-Spector: …might be. We have the same folds in the brain, but probably your brain, cuz you’re male and I’m female is larger than me. So there cannot be a one-to-one mapping from…
[00:17:16] Russ Altman: Right.
[00:17:16] Kalanit Grill-Spector: …each neuron in my brain to each neuron and your brain. Right?
So, How to kind of align brains is not a trivial problem in the first place.
[00:17:25] Russ Altman: Yes, yes. Okay. That actually, that was exactly the question I was going to, which [00:17:30] is are there differences based on things like age and sex in the signals that you’re seeing other than just trying to map them? Like would you expect that if you can map your brain and my brain that we will have very similar responses, or could there be differences based on differences in age or sex or other biological features.
[00:17:52] Kalanit Grill-Spector: So there are definitely differences in age and development, and this is why I’m studying children and babies.
[00:17:58] Russ Altman: Yes.
[00:17:58] Kalanit Grill-Spector: So we can see things that [00:18:00] are changing, uh, over time and things that are different. However, there’s. Surprisingly, a lot of similarities between our brains. So one of the things that we’ve, that got me started thinking about structure is that face area are in a structure in the brain called the fusiform gyrus.
Fusiform means spindle in Latin, and that basically structure looks like a spindle. That structure. It’s, um, has a little bit of a little valley inside the groove. It’s called the mid fusiform gyrus. It’s really small and it’s variable in [00:18:30] size across people, but we found that just finding this anterior tip of this region, um, we, this is very good predictor of where one of the face patches is.
[00:18:39] Russ Altman: Huh.
[00:18:39] Kalanit Grill-Spector: So I can look at your brain and I’m sure we had a very different experience. I grew up in a different country, maybe in a different decade. I had different friends. We saw really different faces in our lifespan. But I have a really good prediction. It’s like 83% predicting your face area just from your anatomy alone, which is crazy.
[00:18:58] Russ Altman: This is the future of [00:19:00] everything. We’ll have more with Kalanit Grill-Spector next.
Welcome back to The Future of Everything. I’m Russ Altman and I’m speaking with Professor Kalanit Grill-Spector of Stanford University.
In the last segment, Kalanit told us about how imaging and computers are revolutionizing the ability of her lab to make accurate measurements of the human brain. It’s giving us a better [00:19:30] understanding of where in the brain we represent different things like faces, objects, scenery, and how they connect to one another.
In this segment, colony will tell us about how brain regions in particular are specialized for certain kind of recognition events, and she’ll tell us that the efficiency and speed of the human brain might help us understand how to build better AI systems.
Kalanit you mentioned maps, you talked about there’s maps of the brain and I just wanna make sure we [00:20:00] understand these maps and what’s the frontiers and understanding and computing about these maps?
[00:20:05] Kalanit Grill-Spector: So, The visual system is really interesting because there are actually maps in the visual system, and you asked me what’s similar across people. This is an example of what’s similar. So for example, uh, when the information gets from your eyes to V1 the primary visual cortex, there’s a map of the visual field. And it turns out that in each visual area that I told you about this hierarchy, There is a mirror reverse map, uh, of the visual field. So there’s one map. There’s also a [00:20:30] map of object categories in your ventral temporal cortex. So…
[00:20:33] Russ Altman: wow.
[00:20:33] Kalanit Grill-Spector: …again, I can predict from the activations, the patterns of activity, what category you’re looking at, and that’s very reproducible across people.
[00:20:41] Russ Altman: Now it’s easy to imagine a map for the visual field because you know, there’s up, down left, right kind of, um, having that, um, I, not to overuse the term, but having that map onto my brain makes sense. But for objects, I don’t think of an obvious way to categorize them. So are you talking about a categorization of objects that is standard or is [00:21:00] it something else?
[00:21:01] Kalanit Grill-Spector: So the map is really interesting because it has several structures. There is like a media lateral division between animate and inanimate stimuli.
[00:21:08] Russ Altman: Ah.
[00:21:09] Kalanit Grill-Spector: And within the animate stimuli you’ll have clusters for faces, for bodies. There’s also a cluster for written words. Um, so, and it’s very reproducible again in terms of the topography on the anatomy of cortex.
And this has been like, Um, really interesting for me because the question is like, are these map just there because of wiring or do they [00:21:30] serve a purpose. So one, you asked me about the frontiers, one of the things that I’ve been working with Dan Yamins, and Eshed Margalit and Dawn Finzi , who are graduate students in my lab, is trying to figure out why these maps arise in the first place, and then what computational values they might serve.
And so we’ve developed this new kind of deep neural network. We call it T DAN or Topographic, deep neural network.
[00:21:55] Russ Altman: Okay.
[00:21:55] Kalanit Grill-Spector: And basically, And usually neural networks learn a task, maybe let’s say object [00:22:00] categorization, or you could have some self supervised learning, just learning the statistics of the world.
But what we’ve tried to kind of implement is a physical constraint of, let’s say, wiring lens. Like maybe the brain has to fit all the wires and like a limited, um, space. So basically we’re trying to put neurons that have similar activity physically. We have a simulated cortical sheet and we’re trying to learn the location and the features of each, let’s say, unit in that [00:22:30] cortical sheet. And it turns out that a very simple constraint, like a wiring constraint and even with a self supervised, uh, learning, um, really predicts not only brain function, uh, but of the brain structure. And the really interesting thing is that it actually predicts brain function better. Then just having a model that doesn’t have this wiring constrain, and that was for me like an aha moment.
[00:22:55] Russ Altman: So what, just to make sure I understand, uh, there is value to taking [00:23:00] all of the, let’s call ’em neurons that are doing similar tasks and putting them together so that they’re closer, so that their connections are a little bit shorter and maybe faster, and that by that organization you get these other phenomenon emerging that might not have been expected. Did I get that right?
[00:23:17] Kalanit Grill-Spector: Perfectly captured.
[00:23:19] Russ Altman: Okay. Alright. And so now you’re, so now it’s a question of getting, my guess is you want to get as high resolution as possible. Uh, you mentioned earlier that you can say it’s a baby, but you might [00:23:30] not know if it’s a baby that I like or a baby. Well, I’d like all babies. Bad example. But if it’s a baby that I don’t know, or a baby I know. So is that one of the opportunities here is higher resolution decoding of the brain regions?
[00:23:44] Kalanit Grill-Spector: Um, yeah, so one is the higher resolution decoding is also acquiring the brain at higher resolution, and people are working on this with seven Tesla scanners that can let you have smaller volume pixels.
[00:23:55] Russ Altman: Yes.
[00:23:55] Kalanit Grill-Spector: And again, collecting a lot of data sets, maybe under different tasks. [00:24:00] Maybe All our data sets right now have still images in real life. You have a continuous stream of visual input, maybe having videos. Um, there are actually multiple processing streams in the brain, and we’ve actually used these topographical deep neural networks also to understand why these streams emerge and maybe give, get new insights about the functions that they might serve.
[00:24:22] Russ Altman: Great. Great. So related to this, I know you have moved your interest as you stated earlier in our conversation to the development of the brain [00:24:30] and to looking at babies and learning at the critical early phases of life. And one of the areas you’ve looked at is reading and looking at the visual visualization of words.
And also I know that this relates somehow to some papers you’ve written, or at least one paper that dealt with Pokemon. So can you tell us about that work and why you’re, what the questions are that you’re asking and what are you learning?
[00:24:52] Kalanit Grill-Spector: So the reason we started looking at kids is that we noticed as adults brain are very similar as we discussed.
I can predict where your face or place [00:25:00] era is just based on anatomy and we were interested to know why that might be. And words are particularly interesting, uh, category because we all are not born with ability to read. And it’s probably two evolutionary reasons that is been carved by evolution. And also you start really becoming expert in reading when you go to school and it’s around like five to seven year olds, depending on the kid and the country.
So this really gives them an opportunity to see how your experience during childhood leads to the [00:25:30] development of new representations in the brain. Um, And there’s a study by a group, uh, in France. Uh, her name is Jill Lambert Dhan, and she showed that this word region emerges during the first year of schooling.
And what we found is that it, it continues actually to develop quite a lot between like age five or six all the way through 17. And it’s also these higher, even the faces you might see early on [00:26:00] even. Your regions that are involved in processing faces continue to develop in childhood in quite a profound way.
And you’re actually better at recognizing faces as an adult than you were when you were five and six year old. So that was kind of really interesting. Um, and one of the surprising things that, and so we were basically measuring brain responses in children over a span of five years. So we can really see the same pixel in the brain, fox in the brain, how it changes…
[00:26:27] Russ Altman: Yes.
[00:26:29] Kalanit Grill-Spector: …over time. And [00:26:30] uh, what we saw that, uh, as specialization for faces and words builds it. Um, we actually saw a decline in the specialization for body parts, especially for hands. And that was really unexpected. Uh,
[00:26:44] Russ Altman: Yeah.
[00:26:46] Kalanit Grill-Spector: Cause. It’s just like people think that maybe experience chisels your brain, but you didn’t think that experience might really change.
[00:26:53] Russ Altman: It maybe even changing your priorities and or, uh, where you focus your cognitive capabilities.
[00:26:59] Kalanit Grill-Spector: Um, Yeah, [00:27:00] so I really think it has to do with the frequency of the stimuli and like your task, maybe a lot of, like you’ve mentioned, social cues. There’s a lot of social cues and faces. Uh, you get a lot of expression and like subtle things about, um, social cognition from eye, uh, movements and stuff like that.
But maybe, uh, when you’re a little kid you get a lot more information, let’s say from. Um, more bigger movements, let’s say, pointing or, uh, and then that becomes really inappropriate later [00:27:30] on. Also, the number of faces, the number of words really increases, uh, over lifespan. The words are longer, more complicated, you know, many more faces, and maybe that’s why these regions really take a very long time to develop.
[00:27:43] Russ Altman: And how does any of this relate to Pokemon?
[00:27:47] Kalanit Grill-Spector: So Pokemon, so, It was pretty clear that, so I told you about the debate about faces, whether it’s an innate or not, it’s very clear that words, um, you have to learn. But the question is, maybe words are [00:28:00] special. Maybe it has to do with something about, you know, symbol systems or culture.
And, um, so we wanted to know if there’s a more general pattern to this. So, uh, my graduate student at the time, he’s now a professor at Princeton, um, Jesse Gomez had his own experience as a kid playing the Pokemon game in the nineties. So it was like this pokey decks, you hold it in your hand. It has really, um, Not just standard graphics. They’re [00:28:30] pixelated objects. They’re smalls, they’re black and white, and it’s kind of a controlled stimulus set because you kind of hold it in your arm length. So there’s some variability, but, and they basically, we were looking at kids at, we were looking at adults that had kids between five and eight, spend hundreds of hours.
Kind of identifying these Pokemon stimuli, uh, and could really determine the difference and comparing to people like me who can tell, pick and choose from everybody else, but that’s about it.
[00:28:57] Russ Altman: Right. So they that I see where [00:29:00] you’re going cuz you’re talking about did this take a part of the brain that then de-emphasized other things that may have been emphasized if they hadn’t been looking at Pokemon so much.
[00:29:10] Kalanit Grill-Spector: Yeah. So we don’t know. Yeah. So we wanted to see further your former representation, whether or not it could not deemphasize anything.
[00:29:17] Russ Altman: Right.
[00:29:17] Kalanit Grill-Spector: It could be just you, maybe you have capacity to code anything.
[00:29:21] Russ Altman: Right? Right.
[00:29:21] Kalanit Grill-Spector: You have, like in the end of the day, billions of neurons who says that you have to
[00:29:26] Russ Altman: push, push something out, right? Maybe you don’t have to push anything out. [00:29:30]
[00:29:30] Kalanit Grill-Spector: Um, so, and the other thing that the Pokemon were interesting is because I told you it was faces. We know that you’re looking at them with fovea words, you’re also looking them, uh, you have to look at words.
[00:29:42] Russ Altman: Yeah.
[00:29:42] Kalanit Grill-Spector: Uh, with the center of gaze, this is where you have your highest visual acuity, and then the Pokemons kind of like really tiny and small, so you also need to look at them with a center of gaze, but they have other characteristics. They’re very pixelated. The place areas really like these, uh, vertical and horizontal lines. So maybe if [00:30:00] it’s something about the visual feature, it might emerge on the place area. They’re also kind of like animate, so maybe it’s really gonna align with animacy.
So it actually lets us give a much more specific hypothesis about one, if the representation is gonna emerge, and then where could be predicted.
[00:30:15] Russ Altman: Yes.
[00:30:15] Kalanit Grill-Spector: Could it be consistent across people, even though it’s a really contrived stimuli. Right?
[00:30:19] Russ Altman: Right. So what did we learn?
[00:30:21] Kalanit Grill-Spector: We learned that one, people who are Pokemon experts do have a special representation for Pokemons.
It’s not like a cartoon general [00:30:30] representation. It’s really specific to Pokemons and it turns out that it shows up on various regions of central gaze. So how you look at the stimulus really affects where is this representation is gonna form and it stays to you till adulthood even then you stop being interested.
[00:30:46] Russ Altman: Right. Right.
[00:30:47] Kalanit Grill-Spector: Maybe Pokemon, maybe in your teens or maybe you’ve never stopped.
[00:30:51] Russ Altman: Now you mentioned that, uh, in the learning of words, that there seemed to be a downgrading of hand focus. Did you see for the [00:31:00] Pokemon, do we have an answer about whether it’s taking its own new space or is it crowding out other, uh, kind of perceptive capabilities in the way that you said that the hands might be downplayed by the growth of words and faces?
[00:31:14] Kalanit Grill-Spector: So I, unfortunately I can’t answer this question. I could answer it in the children because I measured them over five years. So I could go at the end region and see, go backwards in time and see what happened to it when they’re five year old. But here I’ve measured adults.
[00:31:28] Russ Altman: Right.
[00:31:28] Kalanit Grill-Spector: And unfortunately I do not have a time [00:31:30] machine that I can go back in time and see what it was when their five-year-olds before they knew anything about Pokemon.
[00:31:38] Russ Altman: Yes. So, just to finish, uh, up I wanted to talk about your new interest or your new focus on the development of the brain, and we’ve already been talking about that a little bit. Um, are the technologies for making measurements all appropriate and where you need them to be to do this work or do babies and little people, uh, create new technical challenges [00:32:00] for your measurement capabilities?
[00:32:02] Kalanit Grill-Spector: So, uh, I’m very excited about the babies because we think that these, uh, have, uh, the biggest development, uh, and this is why we’re looking at them. Also, we know very little about the baby brains, and one of the things that was really striking and surprising to me is that baby brains look very different than children’s brains.
Um, The structures are not only smaller as they don’t have myelin in the brain, which really puts us at a lot of technical challenge. So we have to [00:32:30] develop new tools to analyze as a field.
[00:32:32] Russ Altman: Yes.
[00:32:33] Kalanit Grill-Spector: Um, baby brains. Uh, and I always like to be in a field that has a lot of new challenges because that’s gonna lead to a lot of new discovery and a lot of new technology development and that makes it extremely, uh, exciting and a hot field to be in.
[00:32:51] Russ Altman: Thanks to Kalanit Grill-Spector, that was the future of human vision. You have been listening to The Future of Everything podcast with Russ Altman. If you enjoy the [00:33:00] podcast, please consider rating and reviewing and following it so you’ll receive news of new episodes, maybe tell your friends about the podcast as well, and definitely rate and review.
We have more than 200 episodes in our archives, so you may want to poke around there for the future of lots of other things. You can connect with me on Twitter @RBAltman and with Stanford Engineering [00:33:30] @Stanford
“Stanford University, officially Leland Stanford Junior University, is a private research university in Stanford, California. The campus occupies 8,180 acres, among the largest in the United States, and enrols over 17,000 students.”
Please visit the firm link to site



